
이번 리뷰할 논문은 GPT-3 입니다.
배경지식
기존 GPT와의 차이점을 간단하게 살펴보면 GPT3는 기존의 GPT1, GPT2 모델에 비해 크기를 엄청나게 키웠습니다.
- GPT-1: 1.17B 파라미터
- GPT-2: 1.5B 파라미터
- GPT-3: 175B 파라미터 (무려 1759억개...)
파라미터 개수를 보면 GPT-2 대비 100배 이상 증가했습니다.
또한 기존 GPT1, GPT2는 주로 Fine-Tuning을 필요로 했고 특정 도메인에 맞게 모델을 추가 학습하는 방식이었습니다. 하지만 GPT-3는 Pre-Trained된 상태에서 추가적인 학습 없이 Zero-Shot, One-Shot, Few-Shot 세팅으로도 충분한 결과를 도출할 수 있다는 것을 보여주었습니다.
(Fine-Tuning은 Gradient Update가 일어나고, N-Shot은 Gradient Update 없이 N개의 예시로 학습을 진행합니다.)
마지막으로 더 기존보다 더 방대하고 질 좋은 데이터셋을 위해 데이터를 정제하는 과정이 강화되었습니다.
1. Abstract
최근 연구에서는 대규모 데이터셋 학습 후 특정 도메인에 대해 Fine-Tuning이 진행되어 좋은 성능을 이끌어냈습니다. 이 또한 상당히 큰 규모의 Fine-Tuning 데이터가 필요합니다.
하지만 인간은 간단하게 몇 개의 예시만 보고도 새로운 작업을 수행할 수 있습니다.
예를 들어,
- 오늘 기분이 안좋아.. ➡️→ 0
- 오늘 날씨가 되게 좋아! ➡️ 1
- 이 영화는 평점 5.0을 받아야 마땅해! ➡️ 1
- 오늘도 야근이네.. ➡️ 0
- 내일은 출근 안한다~ ➡️ ??
물음표에 들어갈 숫자는 0일까요 1일까요? 우리는 당연히 1이라고 답할 것입니다. 몇가지 예시만으로 긍정적은 1, 부정적은 0이라는 것을 쉽게 알아차릴 수 있습니다.
LLM에서도 이와 같이 파라미터 수정 없이 몇가지 예시만으로 학습을 진행하는 것을 Few-Shot Learning이라 합니다.
본 논문인 GPT-3에서는 이 Few-Shot을 통해 SOTA에 근접할만한 성과를 얻을 수 있었다고 말합니다.
(여러가지 실험 결과에 대한 내용은 생략하겠습니다.)
2. Introduce
최근 몇 년 동안의 NLP system은 Pre-Trained을 활용하여 특정 task에 상관없이 사용이 가능한 모델을 연구했고, 이를 DownStream Transfer를 통해 특정 도메인에서 사용할 수 있게 설계되어 왔습니다. 그러므로 특정 task에서 사용하기 위해서는 Fine-Tuning이 필요했습니다.
(* 간략하게 말하면 DownStream Transfer이란, 잘 훈련된 모델에 Fine-Tuning을 통해 특정 도메인에서 사용하는 것을 말합니다.)
이러한 방식은 Tansformer가 등장하면서 많은 발전을 이루어 냈으나 아직 많은 제약이 뒤따르고 있습니다.
2-1. 기존 방식의 문제점
- 첫 째, 특정한 Task에서 사용하기 위해서는 labled된 대규로 데이터셋을 필요로 합니다. 이러한 대규모 데이터셋을 마련하는 것은 쉽지 않아 모델의 활용 범위를 확장하는 것이 어렵습니다. 또한 매 Task마다 이런 복잡한 과정을 반복해야 합니다.
- 둘 째, 거대 언어 모델을 Pre-Trained 한 후 목적에 맞게 Fine-Tuning할 경우 일반화 성능을 잃을 수 있습니다. Pre-Trained 과정에서는 주로 특정 Task에 대한 전문적 지식을 학습 하기보다 일반적인 대화 방법을 학습하게 됩니다. 어린 아이에게 수학, 과학을 가르치는 것이 아니라 맞춤법, 대화하는 방법, 단어 들을 가르치게 되는 것과 같습니다.
문제는 Fine-Tuning을 진행할 때 너무 Specific한 도메인으로 학습을 할 경우 가중치가 과하게 수정되어 일반화 성능이 떨어질 수 있다는 점입니다.
- 마지막으로, 인간은 대부분의 특정 분야의 지식을 배울 때 대규모 데이터셋을 필요로 하지 않는다는 것입니다. 인간은 몇가지 예시를 제시하는 것만으로 특정 Task를 수행할 수 있습니다. 또한 우리들은 '대화'라는 Task를 수행하는 도중 덧셈이라는 다른 Task도 자연스럽게 수행할 수 있습니다.
즉, 한가지 Task에 집중되어 있지 않고 여러 Task를 전환해가며 수행할 수 있다는 것입니다. 언어 모델도 이러한 유연성과 범용성을 확보해야 합니다. AI는 사람의 능력을 구현한다는 점에서 기존의 방식은 괴리가 일어나고 있다는 점입니다.
2-2. 해결 방안
이러한 문제를 해결하기 위해 Meta-Learning 분야가 연구되고 있습니다. Meta-Learning이란, 실질적으로 모델을 학습시키기 위해 Fine-Tuning을 하는 것이 아닌 몇가지 예시를 언어 모델에게 제시하며 맥락을 학습하게 하는 것입니다. 이를 In-Context-Learning이라 합니다. 사실 학습 한다고 보긴 어렵습니다. 모델이 추론을 한다고 생각하는 편이 쉽습니다.

위 사진에 sequence1은 학습이 완료된 모델에게 덧셈에 대한 예시를 몇가지 제시하고 있습니다. sequence2는 오타, sequence3는 언어에 대한 예시를 제시합니다.
간단한 예시 몇가지로 언어 모델은 맥락과 패턴을 파악하여 해당 sequence에 대한 문제를 해결할 수 있습니다. 예시가 늘어날수록, 파라미터 수가 많을수록 정확도는 올라갑니다.
다른 해결 방안으로는 언어 모델의 크기를 키우는 것입니다.
해당 논문이 나올 당시 언어 모델들은 파라미터 개수를 급격히 늘려 모델의 사이즈를 키우는 것이 트렌드였습니다. 당연한 말이지만 파라미터 개수가 늘어나면 더 복잡하고 다방면으로 추론이 가능합니다. 위 사진을 다시 보면 모델의 사이즈가 가장 큰 파란색 그래프의 Accuracy가 가장 높은 것을 볼 수 있습니다.
2-3. GPT-3의 방식
그래서 GPT-3는 이러한 문제를 어떻게 개선했을까?
175B의 파라미터 수를 가진 GPT-3는 Auto-Regressive Language Model입니다.
(* Auto-Regressive 모델은 연속된 단어의 다음 단어를 맞추는 방식으로 학습한 모델을 의미합니다.)
본 논문은 Pre-Trained된 GPT-3에 in-context learning 성능을 아래 3가지 방식으로 평가합니다.
- Zero-Shot Learning: 예시 없이 사전 학습된 내용으로만 특정 Task 수행
- One-Shot Learning: 단 하나의 예시로 특정 Task 수행
- Few-Shot Learning: 여러 예시로 특정 Task 수행 (일반적으로 10~100개)
여기서 예시라 함은 아래와 같은 것을 의미합니다.
ex) bannaa -> banana (오타 교정 예시)

위 사진의 X축은 예시의 개수, 왼쪽 y축은 정확도, 오른쪽 y축은 파라미터의 개수를 나타냅니다.
그래프를 보면 예시의 수가 늘어나고 파라미터 수가 늘어날수록 더 좋은 정확도를 보인다는 것을 알 수 있습니다. 즉, GPT-3는 In-Context-Learning과 모델 사이즈를 급격하게 키우는 방법을 택한 것입니다.
(현재는 175B라는 수가 그다지 커보지이 않을 수 있지만 논문이 나올 당시 아주아주 거대한 모델이었습니다. 물론 더욱 큰 모델이 금방 등장했지만..)
3. Approach
GPT-3의 사전 학습 방식은 기존의 방식과 유사합니다. 차이점은 모델 크기 확장, 데이터셋의 규모와 다양성, 학습 시간 정도일 것 같습니다.
GPT-3는 4가지의 접근법을 가지고 이들의 차이점을 비교합니다.

1. Fine-Tuning
- 최근 가장 널리 쓰이고 있는 방식입니다. Pre-Trained 모델에 추가적인 학습으로 가중치를 업데이트합니다. 대게 데이터셋은 수천에서 수십만개이며 labled 데이터를 이용합니다. Fine-Tuning의 가장 큰 장점은 우수한 성능입니다. 하지만 매 Task마다 새로운 대규모 데이터셋을 요구하고 일반화 성능이 저하될 수 있습니다. 또한 편향의 문제도 있을 수 있습니다. 본 논문의 GPT-3 역시 Fine-Tuning이 가능하지만 N-Shot Learning에 초점을 두고 있습니다.

2. Few-Shot
- Few-Shot이란 모델에게 Task에 대한 예시를 몇 개 제공하는 방식입니다. 물론 가중치 업데이트는 되지 않습니다. context와 completion 쌍으로 예시를 제공하고 마지막에는 맥락만 제시하여 모델이 결과를 생성하게 합니다. 즉 질문과 답변 쌍을 제시하고 마지막에는 질문만 하는 것입니다.
이러한 방식은 Task 별 의존도를 줄일 수 있고 Fine-Tuning의 단점들을 해결할 수 있습니다. 하지만 Fine-Tuning 대비 정확도가 낮고 적은 양이지만 여전히 Task 별 데이터를 필요로 합니다.

3. One-Shot
- Few-Shot과 유사하지만 단 하나의 예시만 주어진다는 것이 차이입니다. One, Few, Zero-Shot을 구분하는 이유는 이러한 방법들이 실제로 사람이 Task를 전달 받는 상황가 가장 유사하기 때문입니다.

4. Zero-Shot
- Zero-Shot은 어떠한 예시도 주어지지 않습니다. 어떤 Task를 수행해야 하는지에 대한 요청과 질문만 주어집니다. (솔직히 성능을 기대하는 것 조차 양심이 없는 것 같습니다...)
일반화 성능을 유지하기에 가장 좋은 방법이지만(당연히 재학습을 안했으니까) 사전 학습된 상태에 의지해야 하기 때문에 높은 정확도를 뽑기 어렵습니다.
본 논문에서는 Few-Shot, One-Shot, Zero-Shot에 중점을 두어 이들의 성능과 효율성을 비교합니다. 특히 Few-Shot의 경우 현재 SOTA 모델들에 비해 약간 뒤쳐지는 정도에 불과합니다.
(SOTA란 State-Of-The-Art의 줄임말로 가장 최신의 혹은 현재 가장 성능이 좋은 것들을 의미합니다.)
3-1. Model and Architectures

위 사진은 GPT-3의 모델 별 세팅을 표로 정리한 것입니다. 모델의 사이즈가 커질수록 다른 수치들도 커지고 Learning Rate만 줄여 세팅했습니다. 제일 아래 마지막 모델이 논문에서 말하는 GPT-3의 본 모델입니다.
3-2 Training Dataset
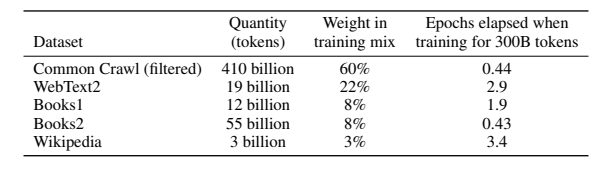
데이터셋의 60%로 가장 많은 비율을 가진 Common Crawl은 그대로 사용할 경우 데이터의 품질이 낮은 경향이 있었습니다. 따라서 high quality reference corpora와 유사도 판별 및 데이터 추가, 중복 제거 등의 기법을 이용하여 데이터 품질을 높였습니다.
또한 데규모 데이터를 이용할 시, 데이터 중복으로 인해 Test Data를 학습하는 문제가 발생할 수 있습니다. GPT-3 학습 도중 이와 같은 문제가 발생하였고 재학습 비용이 너무 비싸 그대로 진행했다고 합니다. 중복이 미치는 영향도 테스트 항목에 추가되었습니다.
(중복을 100% 잡아내는 것은 매우 어려운듯 합니다..)
3-3. Training Process
일반적으로 모델의 사이즈가 커질수록 Batch Size를 크게 잡고, Learning Rate를 작게 잡습니다. GPT-3는 학습 도중 Gradient Noise Scale을 측정하고 배치 크기를 결정하는 방식을 이용했습니다.
(Gradient Nosie Scale이란, 학습 도중 Gradient가 얼마나 크게 달라지는지에 대한 것입니다. 예를 들어 GNS가 클 경우 Gradient가 배치마다 크게 변합니다. 이 경우 Batch Size를 크게 잡으면 학습이 불안정하거나 일반화 성능이 저하될 수 있습니다. 그러므로 GNS 수치를 참고하여 Batch Size와 Learning Rate를 조정하면 안정적인 학습이 가능합니다.)
4. Results
GPT-3의 논문은 테스트 결과들이 40페이지가 넘게 이루어져 있습니다. 이 모든 것을 리뷰하는 것은 불가능하기에 전체적인 결과와 흥미 있는 결과를 몇가지 보여드리겠습니다.
결과적으로 GPT-3는 기존 SOTA 언어 모델을 뛰어넘는 성능을 보여주지는 못했습니다. 하지만 Few-Shot의 경우 특정 Task에서 SOTA 모델을 뛰어넘는 성능을 보여준 결과도 있었고 혹은 약간 미치지 못할 정도의 성능을 보였습니다. Fine-Tuning에 소요되는 데이터셋 준비와 학습 비용 등을 고려하면 굉장히 유의미하고 가치있는 결과입니다.
4-1. Language Modeling
3가지 데이터셋에 대한 평가 결과입니다.

1. LAMBADA는 장기 의존성 포착 성능을 파악할 수 있는 데이터 셋입니다. 긴 문장에 대한 성능을 예측하는 것이기에 긴 문장과 마지막 단어를 예측하는 방식입니다.
Zero-Shot 세팅에서도 무려 SOTA 언어 모델의 성능을 뛰어 넘었습니다.

위 사진은 LAMBADA 정확도에 대한 그래프입니다. 175B인 GPT-3에서는 인간과 비슷할 정도의 정확도를 보였습니다.
재미있는 점은 One-Shot의 성능이 Zero-Shot 성능보다 낮습니다. 우리가 생각하기에 당연히 예시가 없는 것보다는 하나라도 있는게 좋다고 생각할텐데 결과는 그 반대입니다.
논문에서는 이러한 한 단어를 예측해야 하는 문제는 패턴을 인식해야 하기에 여러 예시가 필요하다는 것 같다고 말합니다. 오히려 예시가 주어지지 않으면 언어 모델 자체의 지식으로 처리할 수 있는 것 같습니다.
(예시가 하나만 주어지면 오히려 패턴을 잘못 인식하거나 헷갈려하는 현상이 일어나는 것 같습니다.)
2. StoryCloze은 다섯 문장의 긴 글을 끝맺기에 적절한 문장을 고르는 Task입니다. SOTA 모델을 넘지는 못했지만 10% 안에서 웃도는 성능을 보여주었습니다.
3. HellaSwag는 짧은 글을 끝맺기에 적절한 문장을 고르는 Task입니다. 역시 SOTA 모델 성능의 10% 내의 정확도를 보여주고 있습니다.
4-2. Close Book Question Answering
해당 파트는 GPT-3가 폭 넓은 지식을 묻는 질문에 대답할 수 있는가를 평가합니다. 아래 3가지로 구분하여 테스트를 진행했습니다.
- Natural QS
- 위키피디아에서 추출할 수 있는 정보를 토대로 질문을 합니다. 매우 어렵습니다. 아래 예를 들어보겠습니다.
ex) Q: What is the capital of the state that is home to the University of Alabama?
A: Montgomery
이러한 세밀한 정보를 요구하기 때문에 RAG와 같은 검색 시스템이 없거나 위키피디아를 직접 학습하지 않은 경우 매우 어렵습니다.
- 위키피디아에서 추출할 수 있는 정보를 토대로 질문을 합니다. 매우 어렵습니다. 아래 예를 들어보겠습니다.
- Web QS
- 일반적인 질의를 포함하고 있는 질의응답 데이터입니다. 단답형 답변이 많으며 Natural QS보다는 간결하지만 구조적 지식이 필요한 경우가 많습니다.
- Trivia QA
- 퀴즈 형식의 폭넓은 상식을 요구하는 문제가 주를 이루고 있습니다. 질문과 답변이 비교적 명확하게 이루어져 있어 3가지 데이터 중 가장 간단하다고 볼 수 있습니다.

NaturalQS나 WebQS의 경우 Specific한 답변을 요구하는 질문이 많기에 성능이 비교적 낮게 나오고 있습니다. 하지만 TriviaQA 정도의 질문은 Few-Shot의 경우 RAG 방식보다 더 높은 성능을 보입니다. 아무래도 질문이 간단하니 사전 훈련된 GPT-3에 이미 이에 대한 개념을 가지고 있었을 것 같습니다.
(그래도 RAG보다 성능이 좋은건 신기함..)
4-3. Translation
영어를 다른 언어로 번역하거나, 다른 언어를 영어로 번역하는 영역입니다.

GPT-3 Few-Shot의 경우 다른 언어를 영어로 번역하는 부분에서는 모두 SOTA를 넘어서거나 그에 준하는 성능을 보여주었습니다. 하지만 영어를 다른 언어로 번역하는 과정은 여전히 어려움을 겪고 있습니다.
5. Limitations
GPT-3는 전작인 GPT-2에 비해 크게 개선되었음에도 불구하고 여전히 뚜렷한 취약점을 여럿 보이고 있습니다.
5-1. 성능적 한계
GPT-3가 생성한 텍스트가 의미를 반복하거나 긴 텍스트를 생성할 때 일관성을 잃고 맥락에 맞지 않는 문장을 생성하는 등의 문제가 발생합니다.
특히 간단한 물리 상식 영역에서 어려움을 보였습니다. 예로 "치즈를 냉장고에 넣으면 녹을까?"와 같은 질문에 제대로 답변하지 못했습니다.
또한 독해 능력은 거의 우연 수준에 머무른다고 말하고 있습니다. (그냥 찍기 수준이라는 것 같습니다..)
전체적으로 성능이 낮거나 높은게 아니라 Task 별로 상이한 결과를 보여준다는 것이 흥미로운 것 같습니다.
5-2. 구조적 한계
GPT-3는 AutoRegressive 모델입니다. 또한 Transformer의 디코더를 활용하기 때문에 양방향의 구조를 가지고 있지 않습니다. 실제로 두 문장을 비교하거나 문장 중간의 빈칸을 채우는 것과 같이 양방향성이 유리한 Task 에서는 GPT-3가 낮은 정확도를 보이고 있습니다.
5-3. 근본적 한계
GPT-3는 모든 토큰에 대해 동일한 가중치를 부여하고 있습니다. 즉, 어떤 토큰이 더 중요하고 덜 중요한지 고려하지 못합니다.
또한 현실의 대부분 문제들은 단순 예측과 거리가 멀다. 하지만 현재의 GPT-3의 경우 무엇인가를 예측하는데 포커스되어 있습니다. 이것이 궁극적인 목표와는 괴리가 있다는 것입니다.
덧붙여 인간이 사는 세상에는 텍스트만 있지 않습니다. 오디오, 이미지, 비디오 등 실상에서는 여러 데이터들이 제공되지만 GPT-3는 텍스트로만 학습이 되어 있습니다. 이것도 Real World와는 거리가 있는 것입니다.
(실제로 향후 GPT-3.5나 이후 모델들은 이러한 한계를 극복했습니다... OpenAI 너는 다 계획이 있었구나..)
5-4. 기타 한계점
여러 한계점들도 적혀져 있는데 간단하게 요약하겠습니다.
GPT-3를 학습시키기 위해서는 인간이 한평생 습득하는 텍스트 양보다 많은 데이터가 필요합니다. 효율이 떨어진다는 말이죠. 본 논문에서는 이러한 데이터들의 품질을 높여 적은 양의 데이터로 성능을 끌어올리는 효율적인 연구가 필요하다고 말합니다.
Few-Shot Learning의 불확실성에 대한 한계도 있습니다. Few-Shot Learning으로 세팅된 GPT-3가 높은 성능을 보였을 때 과연 이 결과가 Few-Shot Learning 때문인건가.. 아니면 Pre-Training이 잘 되어 있는 것인가.. 확실하지 않다는 것입니다.
또한 위에서도 언급했 듯 이러한 모델을 만들기 위한 비용이 미치도록 비쌉니다. 그러니 GPT-3도 중간에 버그를 발견했지만 비용 문제로 그냥 사용해버리는 선택을 했습니다.
마지막으로 XAI에 대해 언급합니다. XAI란 설명 가능한 AI를 의미합니다. 말그대로 언어모델이 왜 이런 답변을 내놓았는지에 대한 설명이 불가능하다는 것입니다.
6. 마무리
평소 GPT-3에 대해 알고 있었지만 논문을 끝까지 리뷰한 적은 없었습니다. 오히려 GPT라는 것이 우리에게 너무 가까이 있어 그랬던 것 같습니다.
해당 논문이 나온지 5년 밖에 지나지 않았지만 지금와서 읽어보니 아주 익숙하고 당연한 말들이 많았습니다. 논문이 나올 당시에는 혁신적이고 참신한 방식이었겠죠. 그만큼 NLP/LLM 분야가 정말 활발히 연구되고 빠르게 발전하고 있는 것 같습니다.
특히 Zero-Shot 성능이 One-Shot보다 높은 성능을 보인 Task가 있다는 것이 흥미로웠고 SOTA를 넘는 성능을 보였다는 것이 신기했습니다.
'논문리뷰' 카테고리의 다른 글
| [논문리뷰]Transformer: Attention Is All You Need [2] (1) | 2024.10.07 |
|---|---|
| [논문리뷰]Transformer: Attention Is All You Need [1] (0) | 2024.10.07 |
| [논문리뷰] Continual Learning with Deep Generative Replay (2) | 2024.10.03 |
| [논문 리뷰] Overcoming catastrophic forgetting in neural networks (0) | 2024.09.25 |