
이번 논문은 그 유명한 Transformer입니다. Transformer는 기존의 RNN, CNN 기반 모델들에서 벗어나 오직 Attention 기법만을 이용해 설계했습니다. 현재 GPT, BERT 같은 널리 쓰이는 모델의 근간이 되는 아키텍처입니다. 또한 대부분의 언어 모델들은 Transformer를 기반으로 작동한다 해도 과언이 아닙니다.
기존의 방식들은 단어를 순차적으로 연산하는 직렬 연산으로 작동했습니다. 이러한 방식은 연산 시간이 매우 오래 걸린다는 치명적인 단점이 있습니다. 하지만 Transformer는 Attention만을 사용하여 문장 자체를 한 번에 입력하는 방식으로 병렬 연산으로 작동합니다. 이는 GPU를 효과적으로 사용할 수 있고 연산 시간 또한 획기적으로 단축되는 결과를 가져왔습니다.
이제 논문을 보며 관련 개념들을 하나하나 설명하는 방식으로 리뷰를 해보겠습니다. 논문의 내용을 포함하여 개인적인 해석이 같이 있으므로 본 포스팅은 단순한 논문 번역이 아님을 미리 알려드립니다!!
0. Abstract
기존의 Sequence Transduction 모델들은 복잡한 RNN 또는 CNN을 기반으로 하며 인코더와 디코더를 포함하고 있습니다. 기존의 성능이 우수한 모델들은 이 메커니즘을 따르며 Attention 기법을 통해 성능을 강화했습니다. 하지만 본 논문은 이러한 복잡한 메커니즘을 대체할 수 있는 Transformer를 제안했습니다. Transformer는 오로지 Attention 메커니즘에만 의존합니다. 이러한 방식은 기존 RNN, CNN 기반의 모델들보다 우수한 성능을 보였으며 병렬화를 통해 연산 시간을 단축시켰습니다. 영어를 다른 언어로 번역하는 테스트 결과에서 Transformer 모델은 기존 모델들보다 훨씬 적은 훈련 시간에 더 우수한 성능을 보였습니다. 또한 Transformer는 단순히 번역뿐만 아니라 다른 task에서도 일반화가 될 수 있습니다. 대표적으 구문 분석 분야에서 우수한 결과를 보였습니다.
1. Introduction
기존의 순환 모델은 일반적으로 입력과 출력 시퀀스의 순서에 따라 계산합니다. 즉, 입력 순서를 정렬하고 그 순서에 따라 각각 연산을 처리합니다. 이 순서에 따라 hidden state를 갱신하는 방식으로 동작합니다. hidden state를 갱신하며 문장 간의 관계를 파악하는 것입니다. 이러한 방식은 순차적으로 진행되기 때문에 병렬 처리가 불가능하며 sequence 길이가 길어질수록 메모리 및 속도 문제가 발생합니다.
Attention 기법이 등장하고 기존의 방식과 결합하여 단어 간 중요도를 계산하고 가중치를 다르게 하여 hidden state를 업데이트하는 방식으로 발전되었습니다. 하지만 RNN 기반의 방식을 이용하는 것은 같았기에 기존의 문제가 완전히 해결되지는 못했습니다.
본 논문의 Transformer 모델은 이러한 순환 기법을 완전히 제외하고 전적으로 Attention 기법에만 의존합니다. 이 방식은 순차적인 입력이 불필요하기 때문에 병렬 처리가 가능합니다. Transformer는 8개의 P100 GPU에서 12시간 훈련만에 좋은 성능을 보였습니다.
간단히 정리하자면 기존의 RNN, LSTM 등의 순환 방식에서는 순차적 입력이라는 특성 때문에 직렬 연산으로 작동하였고 이는 메모리와 연산 시간에 있어 한계가 있었습니다. Attention 기법이 도입되고 문제는 완화되었지만 순환 기법을 사용하는 근간은 여전했기 때문에 해결책이 되지는 못했습니다. 본 논문에서 제안된 Transformer 모델은 이러한 순환 기법을 완전히 제외하고 오직 Attention 기법만을 사용하여 기존의 모델들보다 좋은 성능을 보였고 메모리 및 연산 문제를 해결했습니다. 그 이유는 바로 병렬화입니다. Transformer 모델은 Attention 기법만을 사용하기 때문에 병렬화가 가능했고 이는 기존의 모델의 문제를 모두 해결했을 뿐더러 더 좋은 성능을 보였습니다.
2. Background
다양한 백그라운드 모델들이 나와있지만 Transformer에 관련된 중요 부분만 발췌해서 보겠습니다. Multi head Attention은 매우 중요한 개념이지만 다음 내용에 더 자세히 설명되어 있으니 이 부분에서는 넘어가겠습니다.
2.1. Self-Attention
self attention은 자신의 문장에 대해서 attention 기법을 수행하는 것입니다. 예를 들어 he is tom 이라는 문장이 있다고 가정하겠습니다. he, is, tom 이 3개의 단어에서 각각의 관계를 파악하는 것입니다.
| he | is | tom | |
| he | 1.0 | 0.3 | 0.9 |
| is | 0.3 | 1.0 | 0.3 |
| tom | 0.9 | 0.3 | 1.0 |
많은 과정이 생략되었지만 결과만 보면 이런 형태로 관계가 파악됩니다. he는 tom을 의미하므로 큰 값을 가지고 is와는 작은 값을 가지게 됩니다.
3. Model Architecture
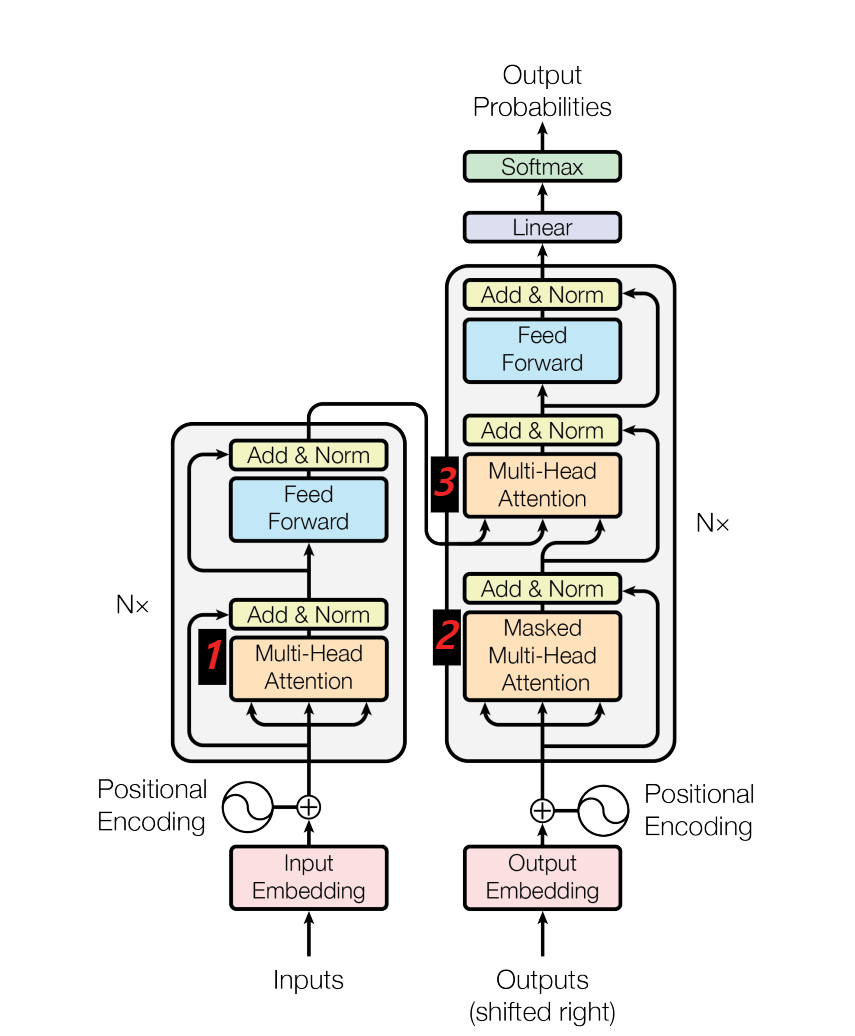
대부분의 sequence transduction 모델을은 encoder-decoder 구조를 따르고 있습니다. 인코더에 총 n개의 ($x_1$ ~ $x_n$)로 이루어진 입력 시퀀스가 있을 때 이것을 ($z_1$ ~ $z_n$) 임베딩 벡터 형태로 변환합니다. 디코더에 z가 주어졌을 때 디코더는 ($y_1$ ~ $y_n$)의 출력 문장을 만들어내는 것으로 동작합니다. 순환 모델들은 이 시퀀스의 길이만큼 네트워크에 입력이 주어지는 방식으로 동작합니다.
Transformer 모델도 위와 같은 인코더-디코더 구조를 따릅니다. 하지만 순환 모델과는 다르게 입력 시퀀스가 한 번에 input으로 주어집니다.
(이 부분에서는 간단하게 구조를 파악하고 아래 카테고리에 더 자세한 설명이 이어집니다.)
인코더 부분부터 보겠습니다.
위 이미지는 전체적인 Transformer의 구조입니다. 순환 기법들은 순차적으로 입력되기 때문에 순서를 파악할 수 있습니다. 하지만 Transformer는 병렬적으로 한 번에 입력 시퀀스가 주어지기 때문에 모델이 순서를 파악할 수 없습니다. 이 순서에 대한 정보를 알려주기 위해 Positional Encoding을 사용합니다. Input Embedding + Positional Encoding을 통해 입력된 문장의 의미와 순서를 표현합니다.
각각의 Attention은 기본적으로 모두 Multi-Head Attention을 사용합니다. Multi-Head Attention은 단순하게 Attention을 여러번 병렬적으로 사용했다고 이해하면 쉽습니다. 이미지에 표시해놓은 1번에서는 입력 문장에 대한 Self-Attention을 수행합니다.
그 다음으로는 기울기 소실 예방을 위해 Residual Connection과 정규화 과정을 거치게 됩니다. (Add&Norm)에서 이 과정이 일어납니다. Feed Forward 레이어를 거치고 다시 Add&Norm 과정을 거치게 됩니다.
인코더에 모든 과정에서 입력 차원은 유지됩니다.즉, Input Embedding의 형태가 (4x4)라면 인코더 레이어를 모두 거쳐도 (4x4)가 출력됩니다. 같은 차원을 유지하면서 총 N번의 인코더 레이어를 거치게 됩니다. N번의 레이어를 모두 통과하고 나온 결과는 화살표 부분을 보면 디코더의 중간으로 들어가게 됩니다.
다음 디코더 부분을 보겠습니다.
디코더에서도 동일하게 Positional Encoding을 더해주고 2번에서 Self-Attention을 수행합니다. 그런데 인코더와 다르게 앞에 Masked라는게 붙어있습니다. 이 Masked는 미래 시점의 단어를 볼 수 없도록 만드는 것입니다. 디코더는 현재 시점에서 이전까지의 출력만 참조할 수 있습니다. 일종의 치팅 방지입니다. 학습을 해야 하는데 답안지를 가지고 공부를 하면 학습 능력이 떨어지는 것과 같습니다. 이를 위해 일부분을 가려 학습합니다. "I am happy" 문장이 있다고 가정하겠습니다. I am이라는 단어를 올바르게 생성하기 위해 happy는 masking 처리하여 디코더에서 happy라는 단어를 참고할 수 없게 만드는 것입니다. 마찬가지로 I를 생성할 때에는 am happy를 masing처리하게 됩니다.
인코더와 동일하게 Add&Norm 레이어를 거치고 다시 Attention을 수행합니다. 이 3번 Attention에서는 인코더에서 들어온 시퀀스와 디코더의 시퀀스에 대한 Attention을 수행합니다. 해당 레이어에서 인코더와 디코더의 시퀀스에 대한 관계를 파악합니다. 디코더의 Query와 인코더의 Key, Value를 통해 Attention value를 계산하게 됩니다. Query, Key, Value에 대한 내용은 아래에서 자세하게 설명하겠습니다. 이 과정에서 문장을 출력하기 위해 인코더의 어떤 부분에 집중해야 하는지 파악하는 것입니다.
이 결과를 가지고 동일하게 Add&Norm 레이어와 Feed Forward 레이어를 순차적으로 거칩니다. 그 후 Linear -> Softmax 층을 거치며 학습을 완료하게 됩니다.
이제 정리해보겠습니다. 이미지에 표시한 1번은 인코더의 Self-Attention, 2번은 디코더의 Masked Self-Attention, 3번은 인코더-디코더의 Attention입니다. 이 각각의 Attention을 헷갈려서는 안됩니다.
다음은 작동 과정에 대해 정리해보겠습니다.
- Input Embedding + Positional Encoding
- 인코더와 디코더에서 각각의 시퀀스를 처리합니다.
- 입력된 단어들은 벡터로 변환되고 Positional Encoding을 더하여 최종 벡터를 생성합니다.
- 인코더의 Multi-Head Self-Attention
- 변환된 벡터에 대해 Self Attention을 수행합니다.
- 자신의 문장에서 각 단어들 간의 관계를 파악합니다.
- 인코더의 (Add&Norm) & (Feed Forward)
- Attention 과정을 거치고 Residual Connection, 정규화, Feed Forward를 각각 거치게 됩니다.
- 인코더 -> 디코더
- 1~3번을 N번 거친 결과물은 디코더로 전달됩니다.
- 디코더의 Masked Multi-Head Self-Attention
- 디코더의 출력 시퀀스는 1번 과정과 같이 벡터로 변환됩니다.
- 그 후 Self-Attention 과정을 거치게 되는데 현재 시점 이전의 단어만 참조하기 위해 미래의 단어를 Masking처리하고 Attention 과정을 거칩니다.
- 이를 통해 디코더는 미래 정보를 알지 못한 상태에서 출력을 생성하게 되며 시퀀스를 순차적으로 생성하는 과정을 학습합니다.
- Encoder-Decoder Attention
- 디코더는 인코더에서 넘어온 값과 Attention을 거치게 됩니다.
- 이 단계에서 디코더는 Self-Attention을 통해 얻은 관계 정보와 인코더와의 Attention 정보를 종합하여 최종 출력을 위한 단서를 얻습니다.
- 인코더의 (Add&Norm) & (Feed Forward)
- 인코더와 마찬가지로 레이어를 통과합니다.
- 디코더 또한 5~7번 과정을 N번 거치며 출력물을 생성합니다.
- Linear -> Softmax -> Output Probabilities
- 출력물은 Linear -> Softmax 과정을 거쳐 최종적으로 Output Probabilities를 출력합니다.
- 이 확률 분포에서 가장 높은 확률을 가진 단어가 최종 출력으로 선택됩니다.
이번 챕터에서 Transformer 구조와 전체적인 흐름을 살펴봤습니다.
작성하다보니 글이 너무 길어져서 1편 2편을 나누어 포스팅 하기로 했습니다. 다음 포스팅에서는 각 레이어의 구체적인 수식과 설명을 이어가겠습니다.
2편은 아래 링크를 클릭하시면 됩니다.
https://chlduswns99.tistory.com/58
[논문리뷰]Transformer: Attention Is All You Need [2]
1편에 이어 작성합니다. 아래 링크를 남겨두었으니 1편을 보고 오시는 것을 추천드립니다! 이해를 돕기 위해 3절에서 사용하던 이미지를 다시 불러오겠습니다. 3.1. Encoder and Decoder Stacks먼저
chlduswns99.tistory.com
디스커션 및 오류 지적은 댓글로 남겨주시면 감사하겠습니다!
'논문리뷰' 카테고리의 다른 글
| [논문리뷰]GPT3 - Language Models are Few-Shot Learners (0) | 2025.03.06 |
|---|---|
| [논문리뷰]Transformer: Attention Is All You Need [2] (1) | 2024.10.07 |
| [논문리뷰] Continual Learning with Deep Generative Replay (2) | 2024.10.03 |
| [논문 리뷰] Overcoming catastrophic forgetting in neural networks (0) | 2024.09.25 |
이번 논문은 그 유명한 Transformer입니다. Transformer는 기존의 RNN, CNN 기반 모델들에서 벗어나 오직 Attention 기법만을 이용해 설계했습니다. 현재 GPT, BERT 같은 널리 쓰이는 모델의 근간이 되는 아키텍처입니다. 또한 대부분의 언어 모델들은 Transformer를 기반으로 작동한다 해도 과언이 아닙니다.
기존의 방식들은 단어를 순차적으로 연산하는 직렬 연산으로 작동했습니다. 이러한 방식은 연산 시간이 매우 오래 걸린다는 치명적인 단점이 있습니다. 하지만 Transformer는 Attention만을 사용하여 문장 자체를 한 번에 입력하는 방식으로 병렬 연산으로 작동합니다. 이는 GPU를 효과적으로 사용할 수 있고 연산 시간 또한 획기적으로 단축되는 결과를 가져왔습니다.
이제 논문을 보며 관련 개념들을 하나하나 설명하는 방식으로 리뷰를 해보겠습니다. 논문의 내용을 포함하여 개인적인 해석이 같이 있으므로 본 포스팅은 단순한 논문 번역이 아님을 미리 알려드립니다!!
0. Abstract
기존의 Sequence Transduction 모델들은 복잡한 RNN 또는 CNN을 기반으로 하며 인코더와 디코더를 포함하고 있습니다. 기존의 성능이 우수한 모델들은 이 메커니즘을 따르며 Attention 기법을 통해 성능을 강화했습니다. 하지만 본 논문은 이러한 복잡한 메커니즘을 대체할 수 있는 Transformer를 제안했습니다. Transformer는 오로지 Attention 메커니즘에만 의존합니다. 이러한 방식은 기존 RNN, CNN 기반의 모델들보다 우수한 성능을 보였으며 병렬화를 통해 연산 시간을 단축시켰습니다. 영어를 다른 언어로 번역하는 테스트 결과에서 Transformer 모델은 기존 모델들보다 훨씬 적은 훈련 시간에 더 우수한 성능을 보였습니다. 또한 Transformer는 단순히 번역뿐만 아니라 다른 task에서도 일반화가 될 수 있습니다. 대표적으 구문 분석 분야에서 우수한 결과를 보였습니다.
1. Introduction
기존의 순환 모델은 일반적으로 입력과 출력 시퀀스의 순서에 따라 계산합니다. 즉, 입력 순서를 정렬하고 그 순서에 따라 각각 연산을 처리합니다. 이 순서에 따라 hidden state를 갱신하는 방식으로 동작합니다. hidden state를 갱신하며 문장 간의 관계를 파악하는 것입니다. 이러한 방식은 순차적으로 진행되기 때문에 병렬 처리가 불가능하며 sequence 길이가 길어질수록 메모리 및 속도 문제가 발생합니다.
Attention 기법이 등장하고 기존의 방식과 결합하여 단어 간 중요도를 계산하고 가중치를 다르게 하여 hidden state를 업데이트하는 방식으로 발전되었습니다. 하지만 RNN 기반의 방식을 이용하는 것은 같았기에 기존의 문제가 완전히 해결되지는 못했습니다.
본 논문의 Transformer 모델은 이러한 순환 기법을 완전히 제외하고 전적으로 Attention 기법에만 의존합니다. 이 방식은 순차적인 입력이 불필요하기 때문에 병렬 처리가 가능합니다. Transformer는 8개의 P100 GPU에서 12시간 훈련만에 좋은 성능을 보였습니다.
간단히 정리하자면 기존의 RNN, LSTM 등의 순환 방식에서는 순차적 입력이라는 특성 때문에 직렬 연산으로 작동하였고 이는 메모리와 연산 시간에 있어 한계가 있었습니다. Attention 기법이 도입되고 문제는 완화되었지만 순환 기법을 사용하는 근간은 여전했기 때문에 해결책이 되지는 못했습니다. 본 논문에서 제안된 Transformer 모델은 이러한 순환 기법을 완전히 제외하고 오직 Attention 기법만을 사용하여 기존의 모델들보다 좋은 성능을 보였고 메모리 및 연산 문제를 해결했습니다. 그 이유는 바로 병렬화입니다. Transformer 모델은 Attention 기법만을 사용하기 때문에 병렬화가 가능했고 이는 기존의 모델의 문제를 모두 해결했을 뿐더러 더 좋은 성능을 보였습니다.
2. Background
다양한 백그라운드 모델들이 나와있지만 Transformer에 관련된 중요 부분만 발췌해서 보겠습니다. Multi head Attention은 매우 중요한 개념이지만 다음 내용에 더 자세히 설명되어 있으니 이 부분에서는 넘어가겠습니다.
2.1. Self-Attention
self attention은 자신의 문장에 대해서 attention 기법을 수행하는 것입니다. 예를 들어 he is tom 이라는 문장이 있다고 가정하겠습니다. he, is, tom 이 3개의 단어에서 각각의 관계를 파악하는 것입니다.
| he | is | tom | |
| he | 1.0 | 0.3 | 0.9 |
| is | 0.3 | 1.0 | 0.3 |
| tom | 0.9 | 0.3 | 1.0 |
많은 과정이 생략되었지만 결과만 보면 이런 형태로 관계가 파악됩니다. he는 tom을 의미하므로 큰 값을 가지고 is와는 작은 값을 가지게 됩니다.
3. Model Architecture
대부분의 sequence transduction 모델을은 encoder-decoder 구조를 따르고 있습니다. 인코더에 총 n개의 ($x_1$ ~ $x_n$)로 이루어진 입력 시퀀스가 있을 때 이것을 ($z_1$ ~ $z_n$) 임베딩 벡터 형태로 변환합니다. 디코더에 z가 주어졌을 때 디코더는 ($y_1$ ~ $y_n$)의 출력 문장을 만들어내는 것으로 동작합니다. 순환 모델들은 이 시퀀스의 길이만큼 네트워크에 입력이 주어지는 방식으로 동작합니다.
Transformer 모델도 위와 같은 인코더-디코더 구조를 따릅니다. 하지만 순환 모델과는 다르게 입력 시퀀스가 한 번에 input으로 주어집니다.
(이 부분에서는 간단하게 구조를 파악하고 아래 카테고리에 더 자세한 설명이 이어집니다.)
인코더 부분부터 보겠습니다.
위 이미지는 전체적인 Transformer의 구조입니다. 순환 기법들은 순차적으로 입력되기 때문에 순서를 파악할 수 있습니다. 하지만 Transformer는 병렬적으로 한 번에 입력 시퀀스가 주어지기 때문에 모델이 순서를 파악할 수 없습니다. 이 순서에 대한 정보를 알려주기 위해 Positional Encoding을 사용합니다. Input Embedding + Positional Encoding을 통해 입력된 문장의 의미와 순서를 표현합니다.
각각의 Attention은 기본적으로 모두 Multi-Head Attention을 사용합니다. Multi-Head Attention은 단순하게 Attention을 여러번 병렬적으로 사용했다고 이해하면 쉽습니다. 이미지에 표시해놓은 1번에서는 입력 문장에 대한 Self-Attention을 수행합니다.
그 다음으로는 기울기 소실 예방을 위해 Residual Connection과 정규화 과정을 거치게 됩니다. (Add&Norm)에서 이 과정이 일어납니다. Feed Forward 레이어를 거치고 다시 Add&Norm 과정을 거치게 됩니다.
인코더에 모든 과정에서 입력 차원은 유지됩니다.즉, Input Embedding의 형태가 (4x4)라면 인코더 레이어를 모두 거쳐도 (4x4)가 출력됩니다. 같은 차원을 유지하면서 총 N번의 인코더 레이어를 거치게 됩니다. N번의 레이어를 모두 통과하고 나온 결과는 화살표 부분을 보면 디코더의 중간으로 들어가게 됩니다.
다음 디코더 부분을 보겠습니다.
디코더에서도 동일하게 Positional Encoding을 더해주고 2번에서 Self-Attention을 수행합니다. 그런데 인코더와 다르게 앞에 Masked라는게 붙어있습니다. 이 Masked는 미래 시점의 단어를 볼 수 없도록 만드는 것입니다. 디코더는 현재 시점에서 이전까지의 출력만 참조할 수 있습니다. 일종의 치팅 방지입니다. 학습을 해야 하는데 답안지를 가지고 공부를 하면 학습 능력이 떨어지는 것과 같습니다. 이를 위해 일부분을 가려 학습합니다. "I am happy" 문장이 있다고 가정하겠습니다. I am이라는 단어를 올바르게 생성하기 위해 happy는 masking 처리하여 디코더에서 happy라는 단어를 참고할 수 없게 만드는 것입니다. 마찬가지로 I를 생성할 때에는 am happy를 masing처리하게 됩니다.
인코더와 동일하게 Add&Norm 레이어를 거치고 다시 Attention을 수행합니다. 이 3번 Attention에서는 인코더에서 들어온 시퀀스와 디코더의 시퀀스에 대한 Attention을 수행합니다. 해당 레이어에서 인코더와 디코더의 시퀀스에 대한 관계를 파악합니다. 디코더의 Query와 인코더의 Key, Value를 통해 Attention value를 계산하게 됩니다. Query, Key, Value에 대한 내용은 아래에서 자세하게 설명하겠습니다. 이 과정에서 문장을 출력하기 위해 인코더의 어떤 부분에 집중해야 하는지 파악하는 것입니다.
이 결과를 가지고 동일하게 Add&Norm 레이어와 Feed Forward 레이어를 순차적으로 거칩니다. 그 후 Linear -> Softmax 층을 거치며 학습을 완료하게 됩니다.
이제 정리해보겠습니다. 이미지에 표시한 1번은 인코더의 Self-Attention, 2번은 디코더의 Masked Self-Attention, 3번은 인코더-디코더의 Attention입니다. 이 각각의 Attention을 헷갈려서는 안됩니다.
다음은 작동 과정에 대해 정리해보겠습니다.
- Input Embedding + Positional Encoding
- 인코더와 디코더에서 각각의 시퀀스를 처리합니다.
- 입력된 단어들은 벡터로 변환되고 Positional Encoding을 더하여 최종 벡터를 생성합니다.
- 인코더의 Multi-Head Self-Attention
- 변환된 벡터에 대해 Self Attention을 수행합니다.
- 자신의 문장에서 각 단어들 간의 관계를 파악합니다.
- 인코더의 (Add&Norm) & (Feed Forward)
- Attention 과정을 거치고 Residual Connection, 정규화, Feed Forward를 각각 거치게 됩니다.
- 인코더 -> 디코더
- 1~3번을 N번 거친 결과물은 디코더로 전달됩니다.
- 디코더의 Masked Multi-Head Self-Attention
- 디코더의 출력 시퀀스는 1번 과정과 같이 벡터로 변환됩니다.
- 그 후 Self-Attention 과정을 거치게 되는데 현재 시점 이전의 단어만 참조하기 위해 미래의 단어를 Masking처리하고 Attention 과정을 거칩니다.
- 이를 통해 디코더는 미래 정보를 알지 못한 상태에서 출력을 생성하게 되며 시퀀스를 순차적으로 생성하는 과정을 학습합니다.
- Encoder-Decoder Attention
- 디코더는 인코더에서 넘어온 값과 Attention을 거치게 됩니다.
- 이 단계에서 디코더는 Self-Attention을 통해 얻은 관계 정보와 인코더와의 Attention 정보를 종합하여 최종 출력을 위한 단서를 얻습니다.
- 인코더의 (Add&Norm) & (Feed Forward)
- 인코더와 마찬가지로 레이어를 통과합니다.
- 디코더 또한 5~7번 과정을 N번 거치며 출력물을 생성합니다.
- Linear -> Softmax -> Output Probabilities
- 출력물은 Linear -> Softmax 과정을 거쳐 최종적으로 Output Probabilities를 출력합니다.
- 이 확률 분포에서 가장 높은 확률을 가진 단어가 최종 출력으로 선택됩니다.
이번 챕터에서 Transformer 구조와 전체적인 흐름을 살펴봤습니다.
작성하다보니 글이 너무 길어져서 1편 2편을 나누어 포스팅 하기로 했습니다. 다음 포스팅에서는 각 레이어의 구체적인 수식과 설명을 이어가겠습니다.
2편은 아래 링크를 클릭하시면 됩니다.
https://chlduswns99.tistory.com/58
[논문리뷰]Transformer: Attention Is All You Need [2]
1편에 이어 작성합니다. 아래 링크를 남겨두었으니 1편을 보고 오시는 것을 추천드립니다! 이해를 돕기 위해 3절에서 사용하던 이미지를 다시 불러오겠습니다. 3.1. Encoder and Decoder Stacks먼저
chlduswns99.tistory.com
디스커션 및 오류 지적은 댓글로 남겨주시면 감사하겠습니다!
'논문리뷰' 카테고리의 다른 글
| [논문리뷰]GPT3 - Language Models are Few-Shot Learners (0) | 2025.03.06 |
|---|---|
| [논문리뷰]Transformer: Attention Is All You Need [2] (1) | 2024.10.07 |
| [논문리뷰] Continual Learning with Deep Generative Replay (2) | 2024.10.03 |
| [논문 리뷰] Overcoming catastrophic forgetting in neural networks (0) | 2024.09.25 |