
전편은 아래 링크를 참고 부탁드립니다
https://chlduswns99.tistory.com/42
2024 ICT 한이음 멘토링[3] - STT,TTS 기능 구현 (온디바이스 보이스챗봇)
[1]https://chlduswns99.tistory.com/40 2024 ICT 한이음 멘토링[1] - 프로젝트 선정 및 지원 (온디바이스 보이스챗봇)ICT 한이음 멘토링 프로젝트란?멘토와 멘티가 팀을 이루어 선정한 프로젝트를 약 10개월간
chlduswns99.tistory.com
이번에는 한국어 사전 학습이 되어있는 Llama3를 추가 학습시켜 목적에 맞게 사용할 것입니다. 무인 상점에서 키오스크와 같이 이용이 가능한 형태로 파인튜닝을 진행합니다.
hk code 유튜브의 김효관 교수님 영상을 참고하여 작성했습니다. 아래 예제 코드를 활용하실 수 있습니다.
https://www.youtube.com/watch?v=RrNX04J4r1Y&list=PLXjrhm6Px4U-ppEkJtAlZpSy-_CXlTxdI&index=9
1. 데이터셋 준비
- 먼저 학습시킬 데이터셋을 구하거나 직접 만들어 csv 파일 형태로 만들어 주어야 합니다.
- 데이터셋을 구해서 대량 학습하는게 가장 좋지만, 저는 목적에 딱 맞는 데이터셋이 없어 100개의 행으로 데이터셋을 직접 구성했습니다. 연습에 사용하실 분은 아래 링크에서 다운받아 사용하셔도 됩니다.
https://drive.google.com/file/d/1ta_ssvUDlLq2TYdoHNgcrecI8yAr87_C/view?usp=sharing
traindata_kor.csv
drive.google.com
- 질문은 대화 형태로 반말과 존댓말을 섞어 준비했습니다.
- 재고같은 경우는 나중에 데이터베이스를 연동시켜 답변을 출력할 것이기 때문에 재고 관련 질문은 모두 제외하였습니다.
1-1. 드라이브 연동 및 라이브러리 설치
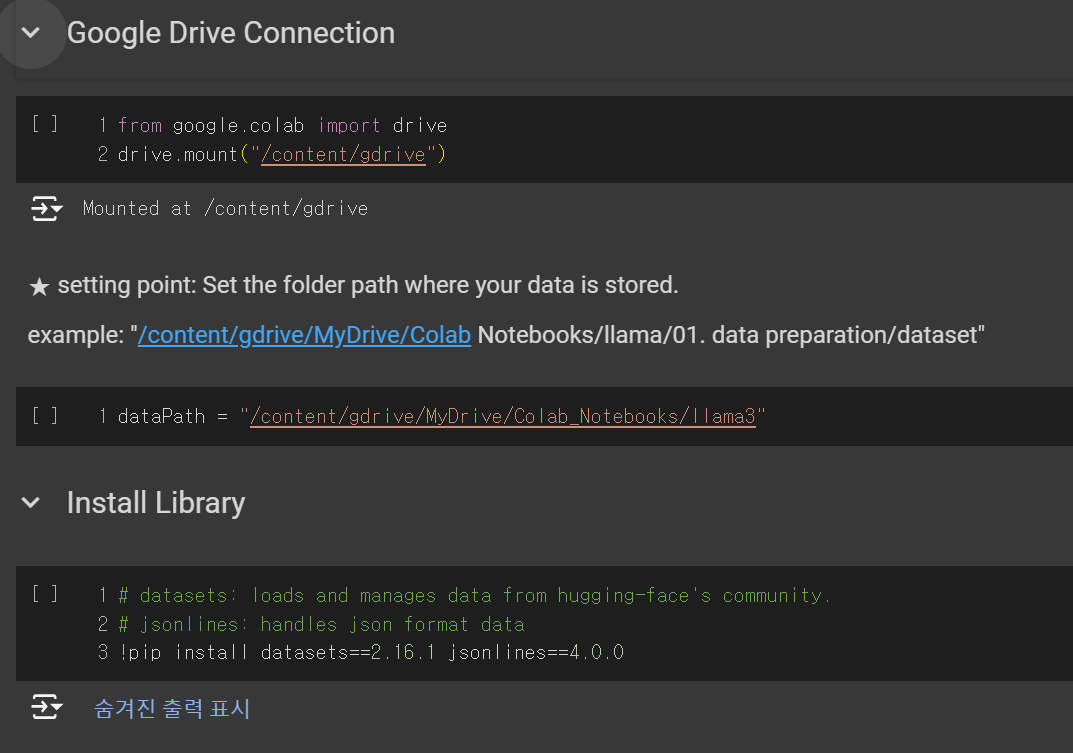
- 먼저 드라이브를 연동합니다. (데이터셋 csv 파일을 드라이브에 업로드 해주어야 합니다.)
- dataPath에는 csv 파일이 저장되어있는 '폴더'를 지정하여야 합니다.(csv 파일의 경로를 입력하는 것이 아님)
- 그 후 필요 라이브러리를 설치합니다.
1-2. 허깅페이스 로그인

- 허깅페이스에 로그인합니다.
- 토큰을 입력하는 칸이 나올텐데 허깅페이스 사이트에 들어가서 Profile -> Setting -> Access Token으로 들어갑니다.
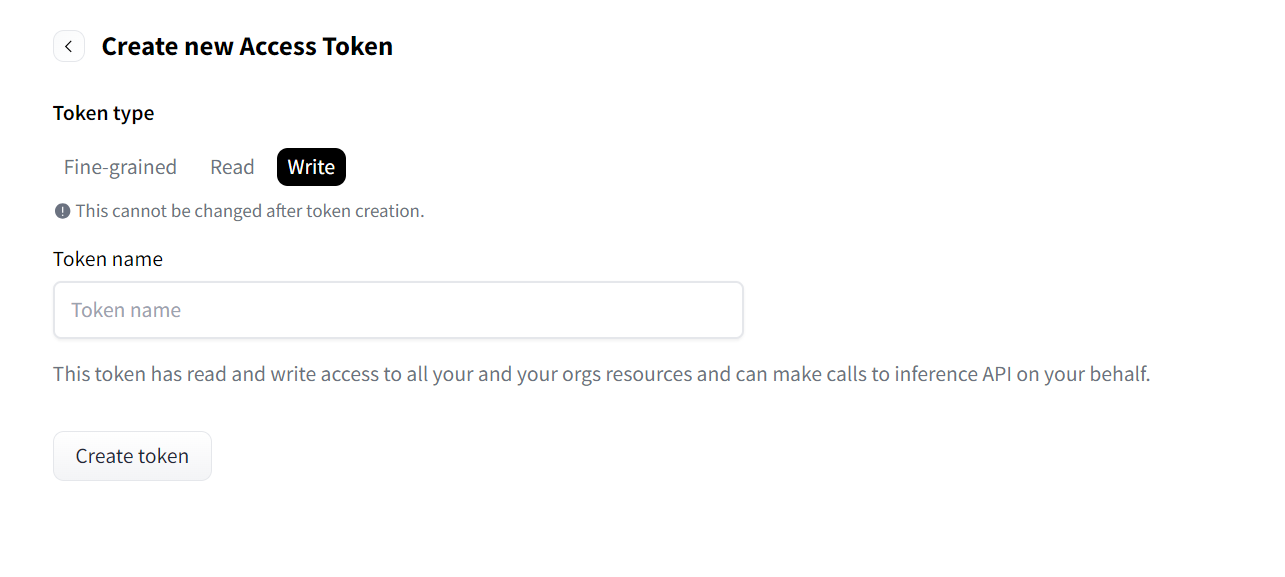
- 토큰이 없다면 토큰을 만들어 줍니다. Write 타입으로 토큰을 생성합니다.
1-3 허깅페이스에 csv 파일 업로드
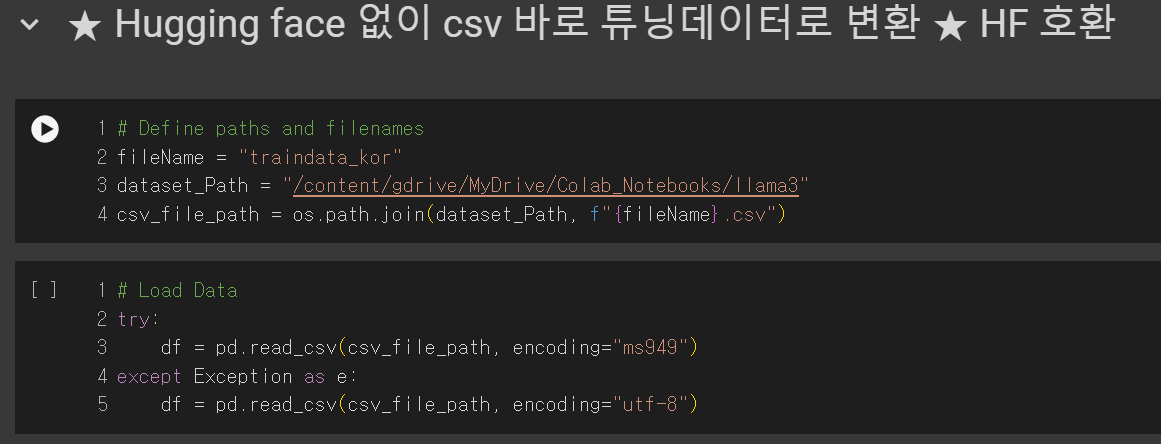
- fileName은 csv 파일 이름으로 지정합니다.
- dataset_Path는 데이터셋 파일이 존재하는 폴더 경로로 지정합니다.
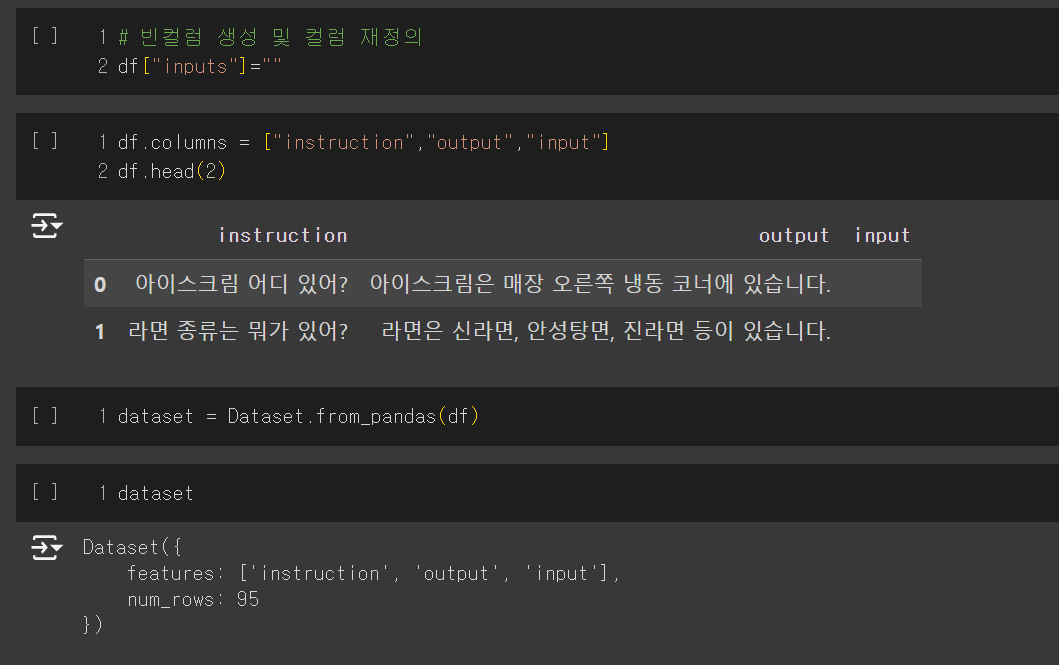
- df["inputs"] = "" 코드를 실행시켜 빈 컬럼을 추가합니다.
- 컬럼 명을 재정의하고 데이터프레임으로 변환해줍니다.
- 확인해보면 instruction, output, input 총 3개의 컬럼이 존재하고 input은 빈 컬럼인 것을 알 수 있습니다.
1-4. 허깅페이스에 데이터셋 업로드
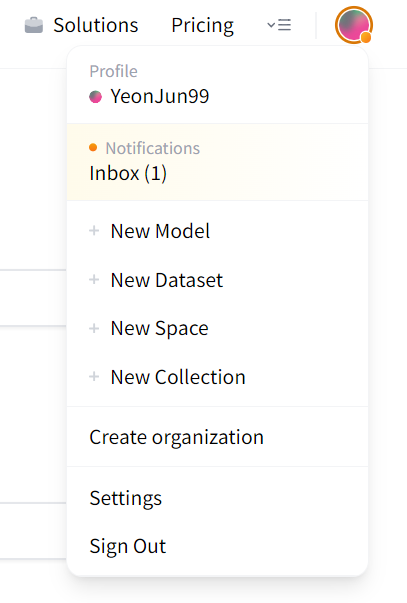
- 이미지처럼 허깅페이스에서 프로필을 클릭하면 New Dataset이 있습니다. 새로운 데이터셋을 생성합니다.
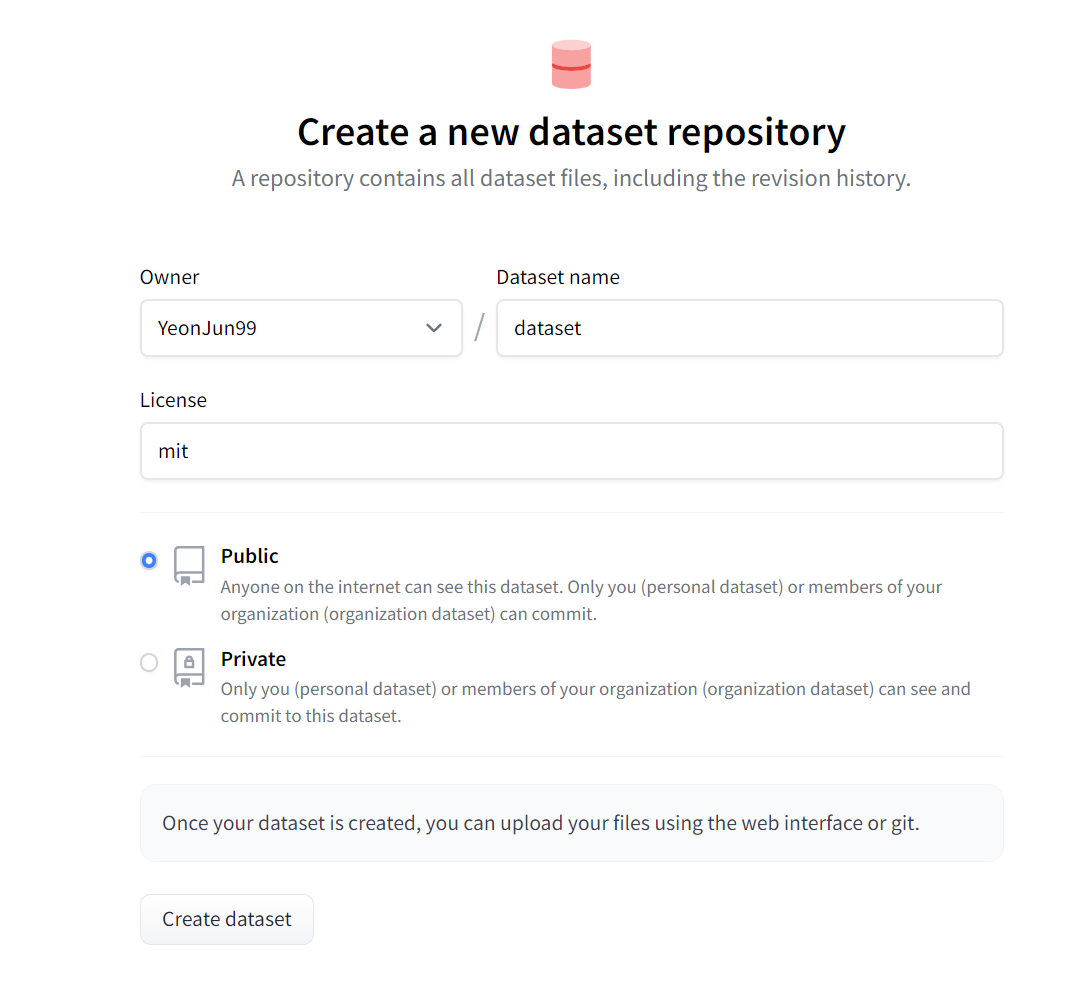
- 이름은 자유롭게 지정합니다.
- License는 mit로 설정합니다.
- 공개 범위는 큰 이유가 없으면 Public으로 설정하시는게 편합니다.

- 만들고 나서 위 코드를 실행합니다. 괄호 안 경로는 허깅페이스에서 만든 Dataset의 경로를 지정해야 합니다.
- 자신이 만든 데이터셋 페이지를 들어가면 경로를 복사할 수 있습니다.
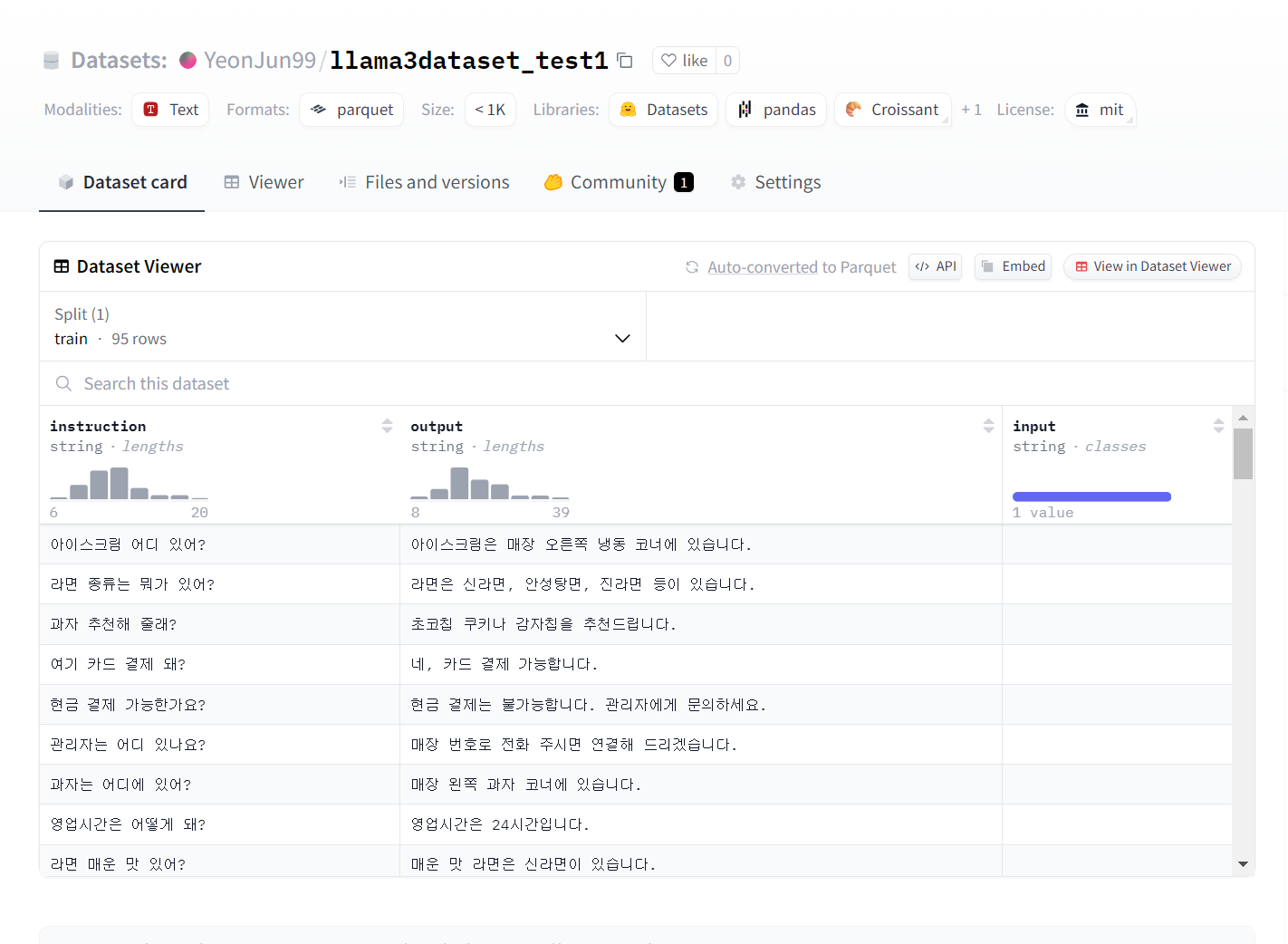
- 데이터셋 페이지에 들어가면 알맞게 들어간걸 볼 수 있습니다.
2. Llama3 파인튜닝(Fine-Tuning)
- 다음은 파인튜닝을 진행합니다.
- 코랩의 무료 GPU로는 금방 사용량이 바닥날테니 유료 플랜을 결제하거나 클라우드 이용을 추천드립니다.
- 저는 코랩 Pro+를 사용중이며 L4 GPU를 사용했습니다. 100개의 데이터를 20에퍽 돌렸을 때 약 20컴퓨팅이 소모되었습니다.
2-1. 모델 설정
- 아래 화면까지 수정없이 실행하시면 됩니다.
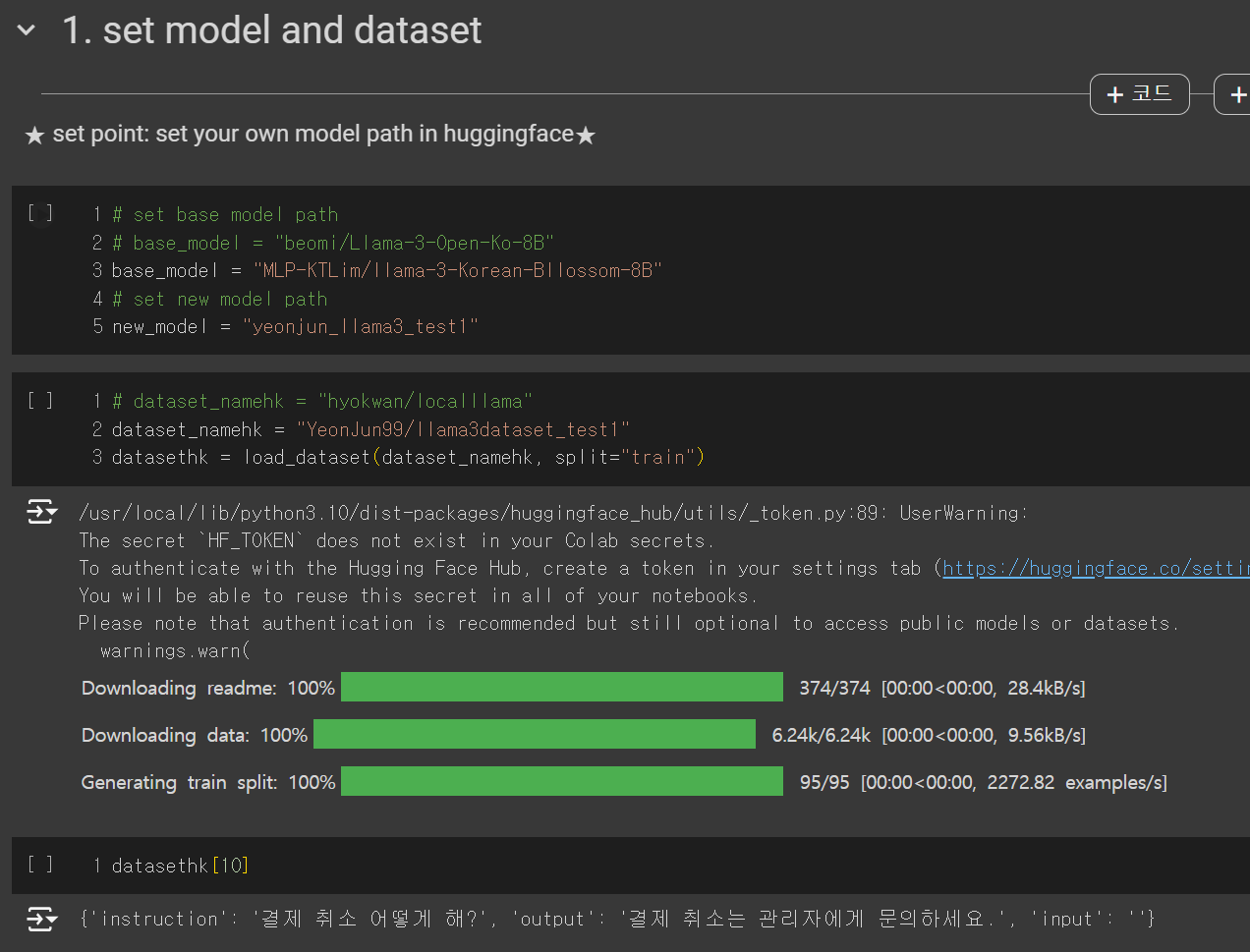
- 먼저 사전 학습된 베이스 모델이 있어야 합니다. 기본 Llama3 모델을 사용해도 되지만 한국어 사전 학습이 되어있는 모델을 사용할 경우 더욱 성능이 좋습니다.
- 저는 아래 링크의 Bllossom 모델을 사용했습니다.
https://huggingface.co/MLP-KTLim/llama-3-Korean-Bllossom-8B
MLP-KTLim/llama-3-Korean-Bllossom-8B · Hugging Face
Update! [2024.06.18] 사전학습량을 250GB까지 늘린 Bllossom ELO모델로 업데이트 되었습니다. 다만 단어확장은 하지 않았습니다. 기존 단어확장된 long-context 모델을 활용하고 싶으신분은 개인연락주세요!
huggingface.co
- 링크 접속 후 상단에 경로를 복사하여 base_model에 지정합니다.
- new_model은 아직 사용하지 않지만 추후 저장할 모델 이름입니다. 자유롭게 지정하면 됩니다.
- dataset_namehk에 허깅페이스 데이터셋 경로를 입력합니다. (변수에 hk가 붙은 것은 코드 제공해주신 교수님의 이니셜이니 수정해도 됩니다.)
2-2. 데이터셋 형식 설정
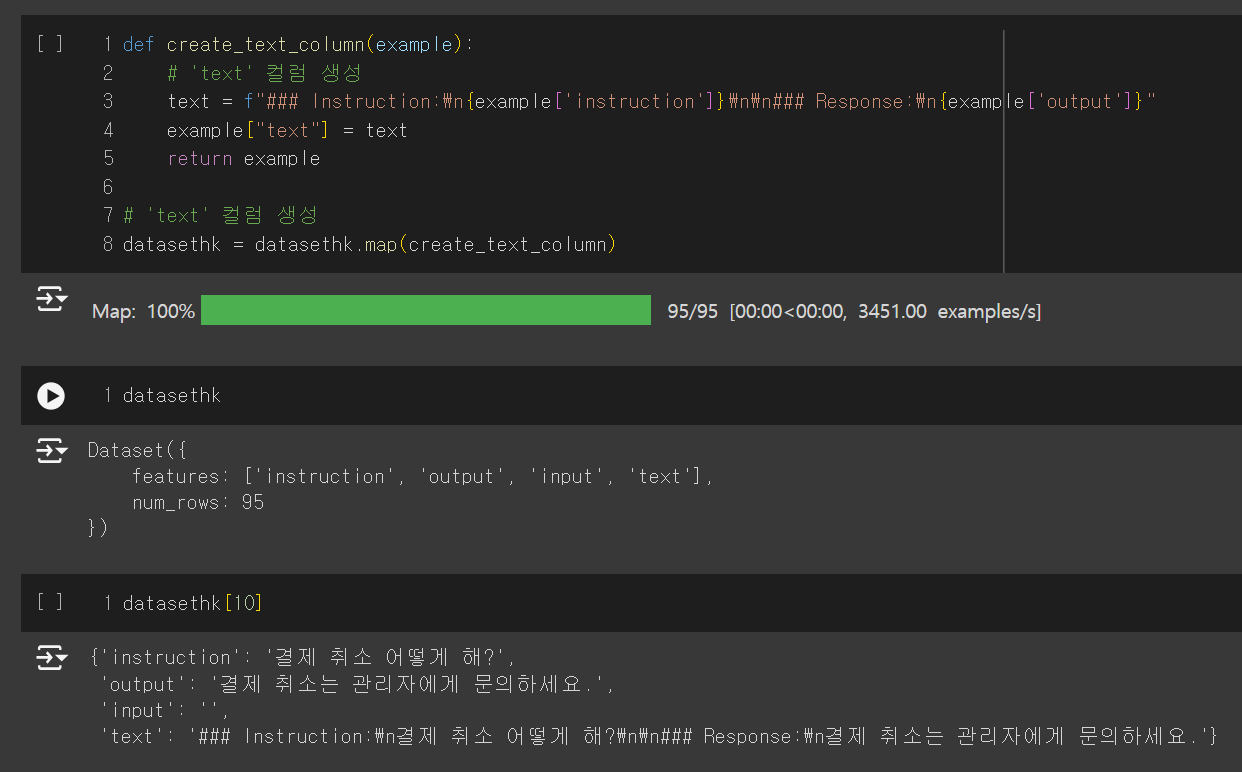
- 함수를 통해 데이터셋에 text 컬럼을 생성합니다.
- 질문과 답변을 하나의 컬럼 안에 넣어서 형식을 맞춰주는 것입니다.
- 마지막 코드 결과를 보면 text 컬럼에 전체적인 질문과 답변이 형식에 맞춰 생성된 것을 볼 수 있습니다.
2-3. GPU 및 양자화 세팅
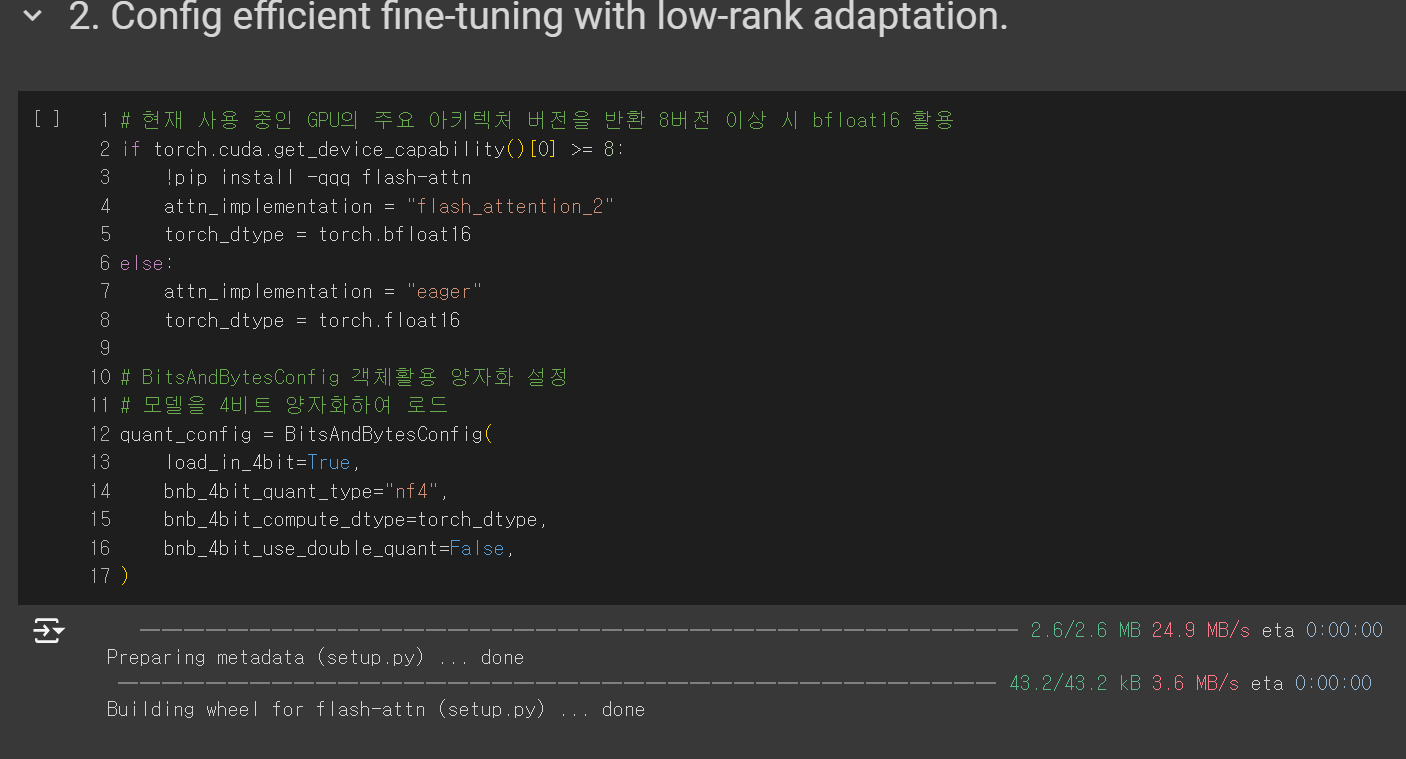
- 먼저 GPU 설정을 해줍니다. 간단히 말해 "GPU 성능이 좋다면 더 고성능 작업을 수행하겠다" 라고 생각하시면 됩니다.
- if문을 보면 GPU의 capability가 8 이상인지 아닌지에 따라 attn_implementation을 다르게 설정하게 되어 있습니다.
- 효율성을 위해 모델을 4비트 양자화하여 로드합니다. 간단히 말해 양자화를 통해 모델의 크기를 줄이는 것입니다. 양자화는 더욱 복잡한 개념이 있지만 양자화를 하는 목적만 알고 넘어가겠습니다.
2-4. 베이스 모델 로드

- 베이스 모델을 로드합니다.
- 위에서 세팅한 내용을 AutoModelForCasualLM.from_pretrained 메서드의 파라미터로 입력합니다.
2-5. 베이스 모델 토크나이저 로드 및 EOS_TOKEN 사용
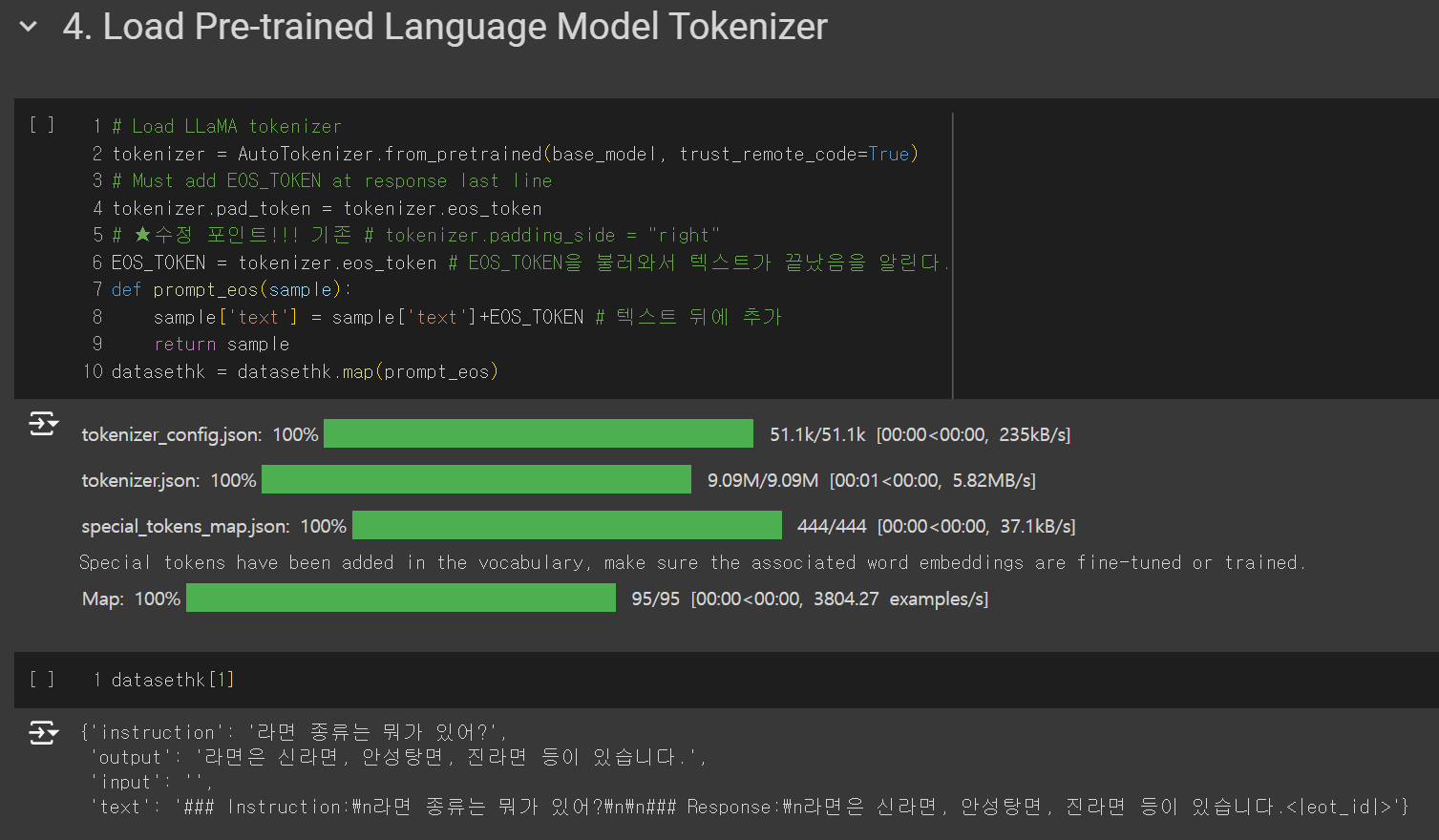
- 베이스 모델의 토크나이저를 로드합니다.
- 중요한 점은 EOS_TOKEN을 이용하는겁니다.
- EOS_TOKEN을 데이터셋의 끝에 추가해 텍스트가 끝났음을 알려주는 용도입니다.
- EOS_TOKEN을 설정하지 않을 시 언어 모델이 같은 답변을 연속하여 출력하는 오류가 날 수 있습니다.
2-6. 하이퍼 파라미터 설정
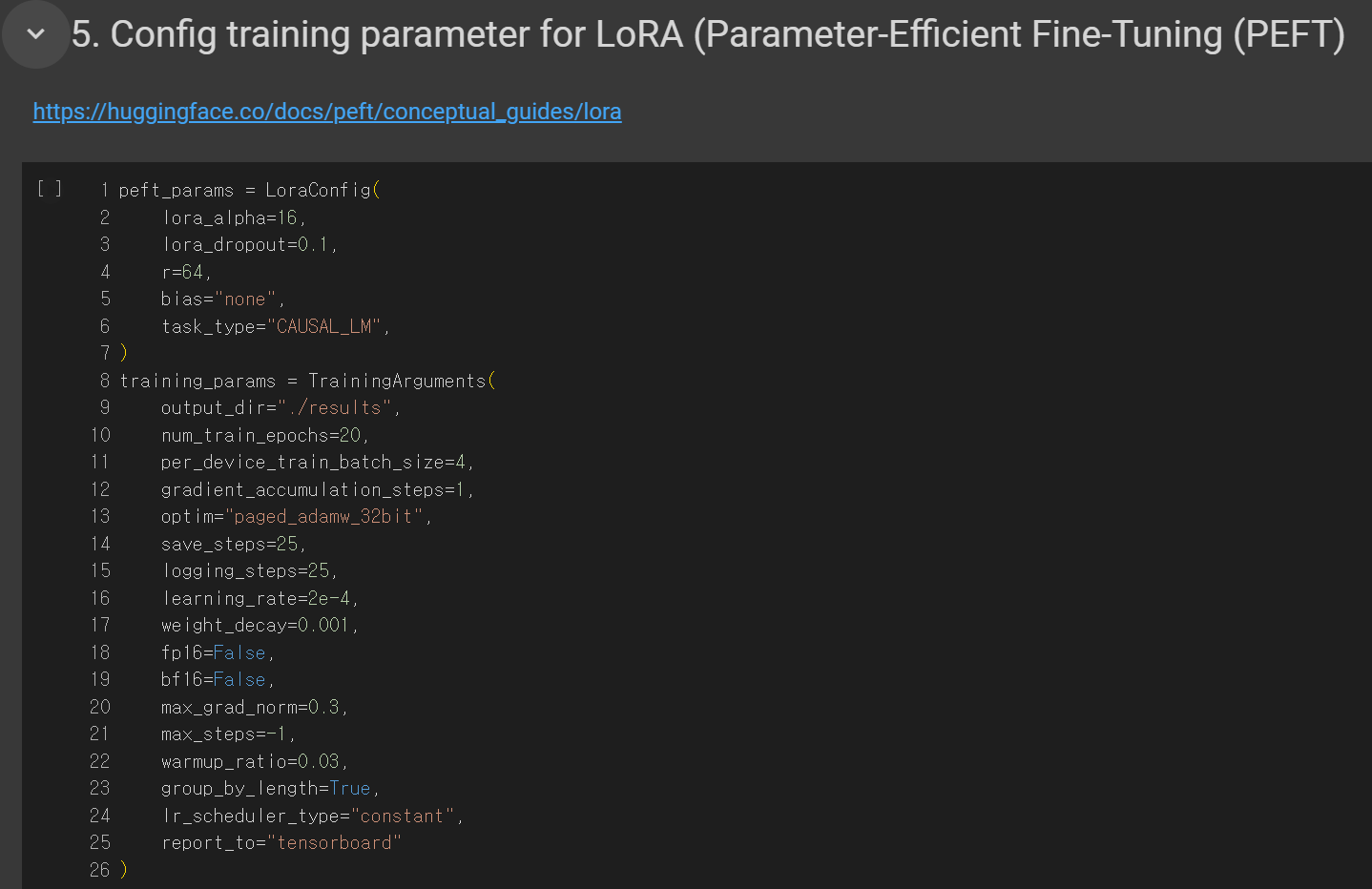
- 학습을 위해 하이퍼 파라미터를 설정합니다.
- 몇가지만 살펴보겠습니다.
- num_train_epochs: 반복 횟수를 지정합니다. 에퍽 수를 높게 잡을수록 오래걸리고 학습량이 늘어납니다. 단점은 과적합이 일어날 수 있다는 점입니다.
- per_device_train_batch_size: 배치 사이즈를 지정합니다. 한번에 학습에 사용할 데이터량이라고 보시면 됩니다. 사양이 좋을수록 배치 사이즈를 높게 잡을 수 있습니다.
- save_steps: 설정한 step마다 Loss를 출력하여 알려줍니다.
- logging_steps: 설정한 step마다 중간 저장을 합니다. 학습량이 많을 경우 logging_steps를 없에거나 늘려주면 용량을 확보할 수 있습니다.
- learning_rate: 학습률을 지정합니다. 학습률이 높으면 과적합이 일어날 수 있기에 주의해서 지정해야 합니다.
2-7. 모델 학습
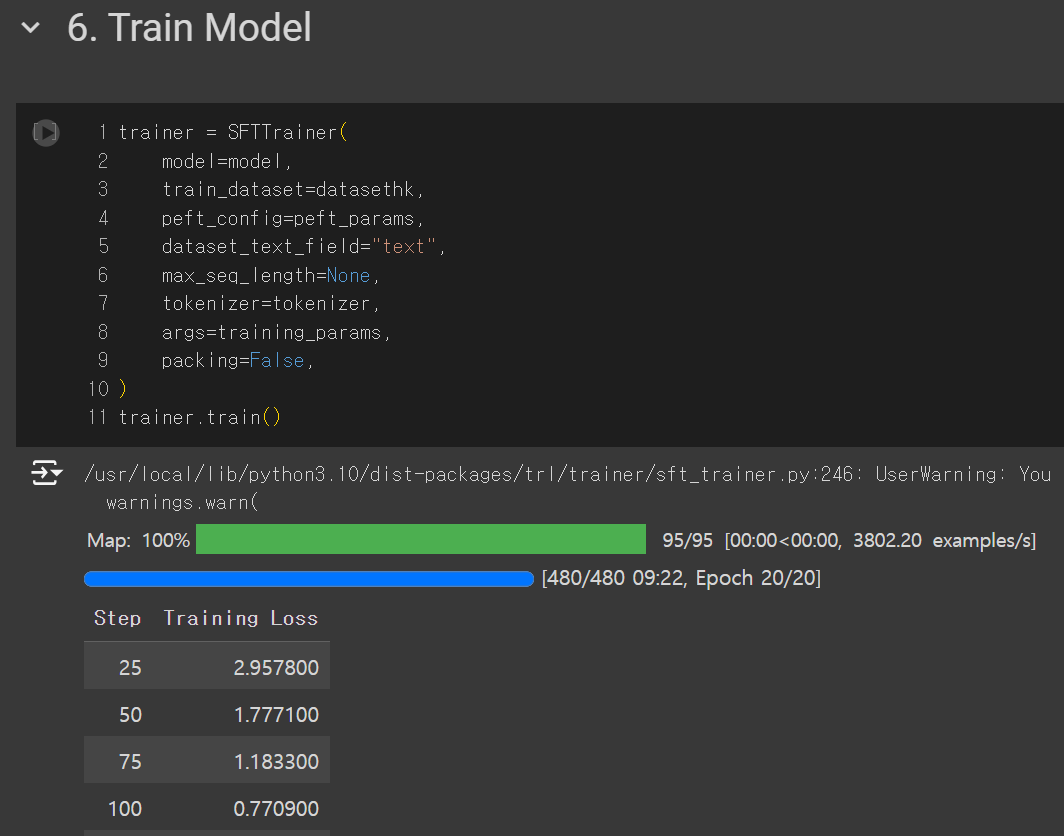
- 대망의 학습 시간입니다.
- 지금까지 지정했던 세팅값들을 모두 입력 후 학습을 시작합니다.
- 저는 100개의 데이터를 20에퍽 학습시켰습니다.
2-8. 답변 출력해보기
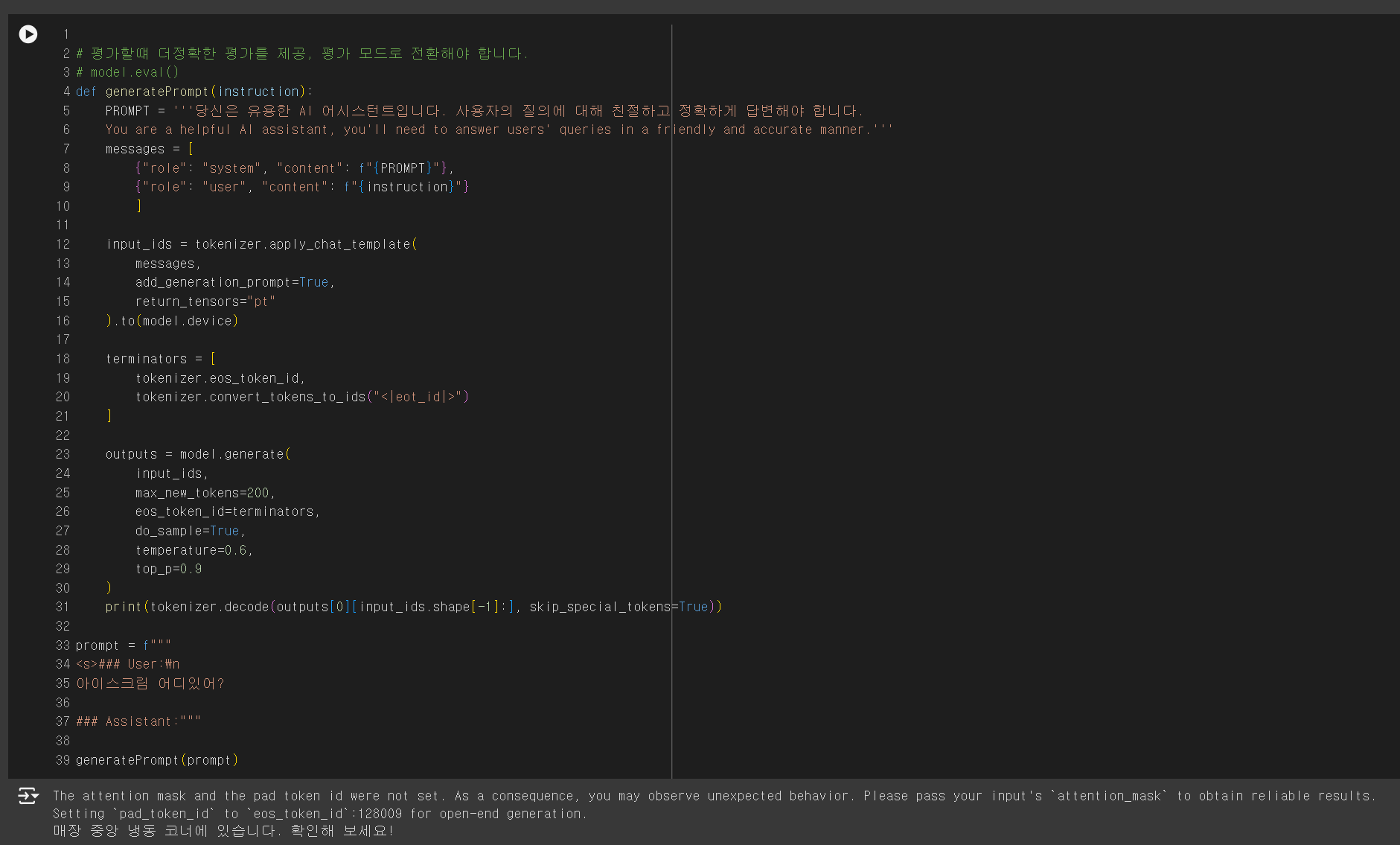
- 사용한 베이스 모델에 따라 약간의 수정이 필요할 수 있습니다.
- 답변이 올바르게 나오지 않을 경우 베이스 모델의 설정 값들을 참고하여 답변이 올바르게 출력될 때까지 조금씩 수정하는 방식을 추천합니다.
- 아래 출력 화면을 보면 답변을 출력합니다.
- "아이스크림 어디있어?"라는 질문에 "매장 중앙 냉동 코너에 있습니다. 확인해 보세요!"라는 답변을 출력했습니다.
2-9. 드라이브에 모델 저장
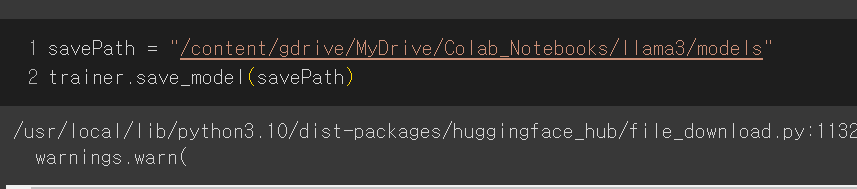
- 저장할 경로를 지정하고 코드를 실행시켜 드라이브에 모델을 저장합니다.
- 꼭 본인의 드라이브 경로로 저장해야 합니다. 코랩에서 지원해주는 저장 공간에 모델을 저장하면 세션 끊으면 다 날라갑니다!
학습량이 턱없이 부족하지만 탄탄한 베이스 모델 덕에 그래도 꽤나 괜찮은 답변을 출력하는 결과가 있었습니다.
추후 추가학습, gguf 포맷 변환, RAG 활용 등의 내용을 업로드할 계획입니다. 모든 내용은 유튜브 hk code 김효관 교수님의 영상을 참고했으니 정말 추천합니다.
'프로젝트' 카테고리의 다른 글
| 2024 ICT 한이음 멘토링[4] - STT,TTS기능 Llama2 연동 (온디바이스 보이스챗봇) (0) | 2024.06.25 |
|---|---|
| 2024 ICT 한이음 멘토링[3] - STT,TTS 기능 구현 (온디바이스 보이스챗봇) (0) | 2024.06.25 |
| 2024 ICT 한이음 멘토링[2] - 한이음 장비 신청, Ollama 설치 (온디바이스 보이스챗봇) (0) | 2024.04.11 |
| 2024 ICT 한이음 멘토링[1] - 프로젝트 선정 및 지원 (온디바이스 보이스챗봇) (0) | 2024.02.29 |